머신러닝 입문 피드백
새싹반 모델링 기초 과정
1. 모델과 가중치 학습
- 수학적 모델: 데이터를 가장 잘 묘사하는 함수식 (예: $y = Wx + b$)
- $W$ (가중치, Weight): 입력 데이터가 결과에 미치는 영향력이나 중요도
- $b$ (편향, Bias): 기본적으로 깔려 있는 기준점 (영점 조절)
- 가중치 학습: 최적의 $W$와 $b$를 찾기 위해 끊임없이 모델을 업데이트하는 과정
선형 회귀와 오차(Loss)
- 오차 계산 방식: MSE (Mean Squared Error) vs MAE (Mean Absolute Error)
- $$ MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 $$
- $$ MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| $$
Q. MAE(절댓값) 대신 왜 기꺼이 오차를 '제곱'하는 MSE를 주로 쓸까요?
(힌트: 미분 가능성, 큰 오차에 대한 강한 패널티)
(힌트: 미분 가능성, 큰 오차에 대한 강한 패널티)
Quiz 🤔
우리의 모델은 도대체 무엇을 하면 좋을까요?
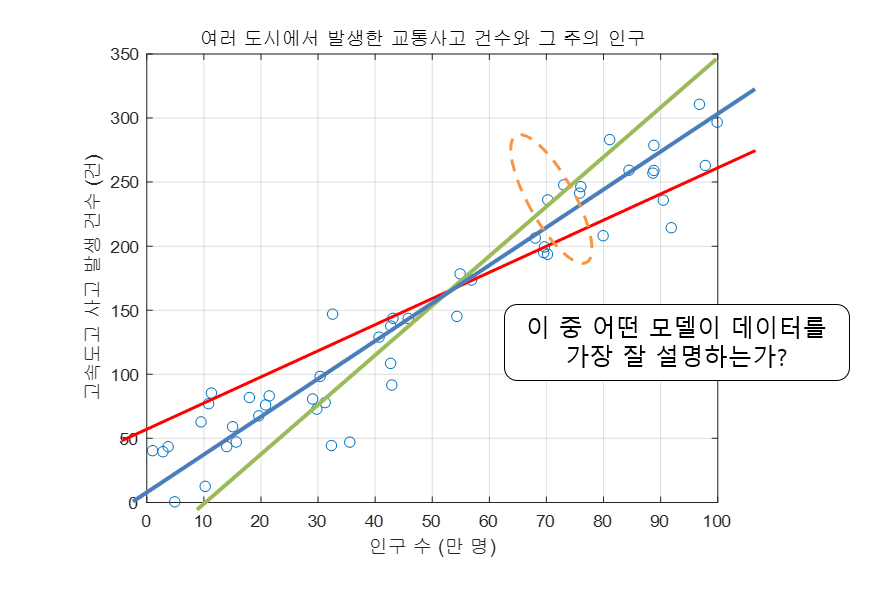
수많은 데이터 점들 사이에서, 과연 어떤 선(모델)이 가장 훌륭한 선일까요?
핵심: 현실의 분포 예측
"모든 머신러닝 모델이 바라는 단 한 가지는,
현실의 데이터 분포를 가장 완벽하게 예측(모방)하는 것"
현실의 데이터 분포를 가장 완벽하게 예측(모방)하는 것"
- 우리가 Loss(오차)를 구하고 가중치를 업데이트(학습)하는 이유는
- 결국 방금 본 사진처럼 현실의 진짜 데이터 패턴을 가장 잘 관통하는 단 하나의 선을 찾기 위함입니다.
2. 경사하강법 (Gradient Descent)
- 미분을 활용해 오차(Loss) 곡면을 따라 최소점(최적해)으로 하강
- 각 단계마다 기울기의 반대 방향으로 가중치 업데이트
$$ w_{new} = w_{old} - \boldsymbol{\alpha} \frac{\partial L}{\partial w} $$
- 학습률($\boldsymbol{\alpha}$, Learning Rate): 한 번의 업데이트마다 이동할 보폭
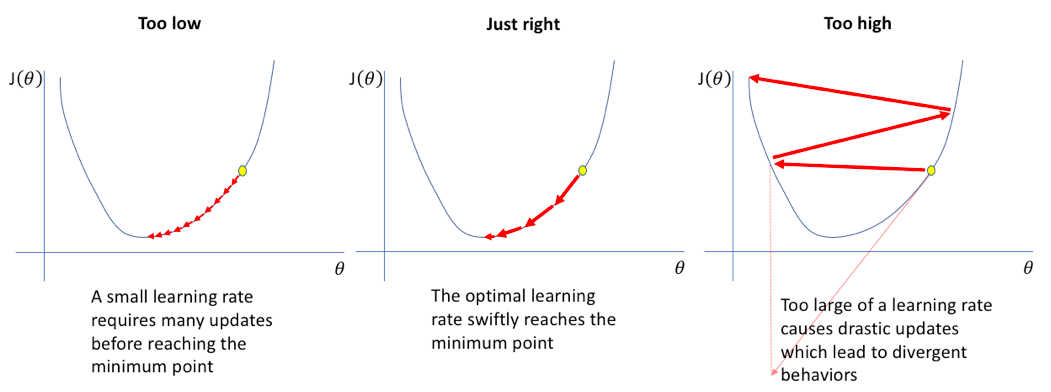
추가 핵심 지식: 최적화와 미니 배치
- 전체 데이터(Full Batch): 1 Step 계산이 무겁고, Local Minimum에 빠지기 쉬움
- 미니 배치(Mini-Batch): 전체 데이터를 잘게 쪼개서 모델에 조금씩 입력하는 방식
- 계산 속도가 빠름
- 지그재그(Noise) 이동이 고립된 곡면(Local Minimum) 탈출을 도움


3. 과적합 (Overfitting)
- 학습 데이터에만 지나치게 맞춰져 새로운 데이터 예측 실패
- 해결: 검증 데이터(Validation)를 통한 Early Stopping
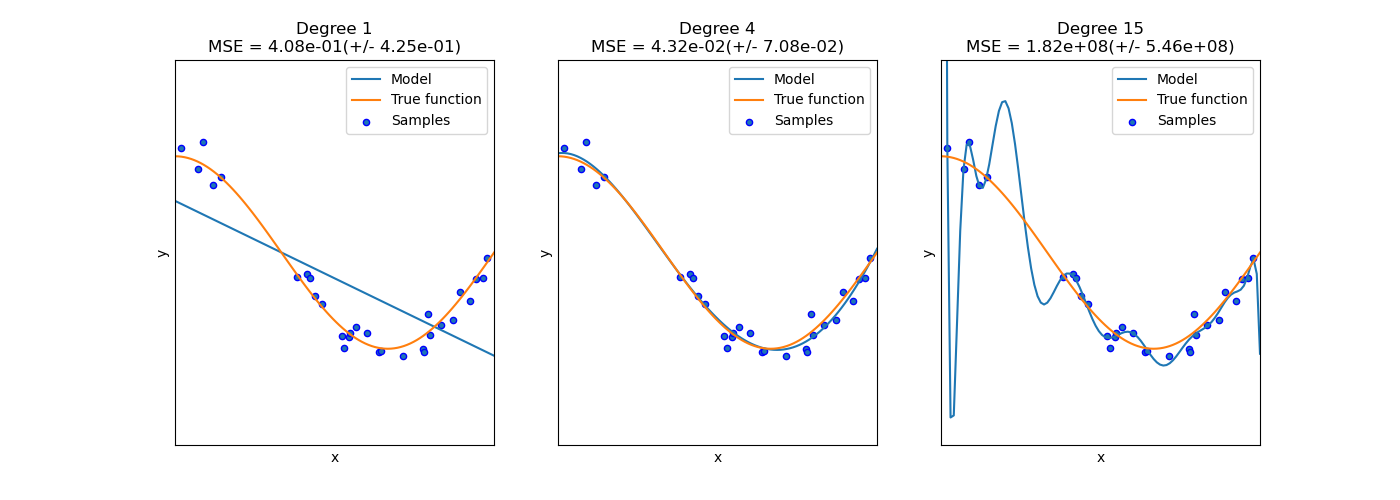
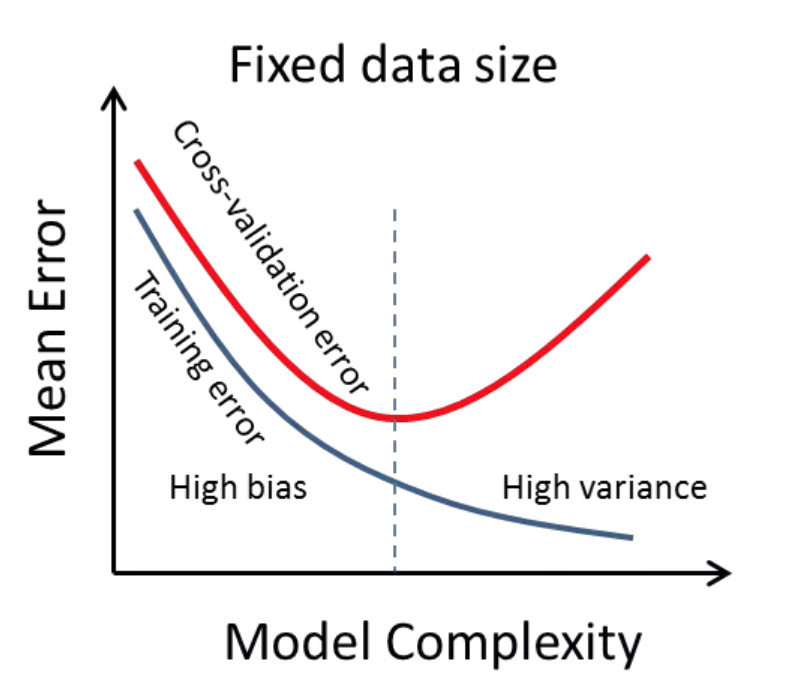
4. Regularization (L1, L2) 예고
- 가중치가 비정상적으로 커지는 것을 규제(Penalty)하여 과적합 방지
- 모델의 복잡도를 낮추는 핵심 수학적 테크닉
- 👉 다음 주 세션에서 수학적 원리와 함께 집중 학습 예정!
5. 로지스틱 회귀: 왜 선형 회귀가 아닐까?
분류(Classification) 문제에서 선형 회귀를 쓰면 생기는 일
- 한계 1. 이상치(Outlier) 취약성:
극단적 수치를 가진 데이터 하나가 합격 선(Threshold) 전체를 왜곡시킵니다. - 한계 2. 값의 결과 범위($-\infty \sim \infty$):
결과값이 끝없이 뻗어 나가므로 이를 우리가 원하는 '0~1 사이의 확률'로 해석할 길이 없습니다.
발상의 전환: 확률 대신 승산(Odds)
- 확률 대신 승산(Odds): $Odds = \frac{p}{1-p}$ (실패 확률 대비 성공 확률의 비율)
예) 합격 확률($p$)이 $80\%$라면, $Odds = \frac{0.8}{0.2} = 4$ (합격 가능성이 불합격보다 4배 높음) - 승산(Odds) 역시 그 범위가 $0 \sim \infty$라서 여전히 음수값을 갖는 선형 회귀($-\infty \sim \infty$)에 대응시킬 수 없습니다.
- Log Odds: 여기에 $\log$를 씌우면 값의 범위가 드디어 $(-\infty, \infty)$로 무한히 확장됩니다!
로지스틱 회귀 = Log Odds의 선형 회귀
- 로지스틱 회귀의 본질은 Log Odds에 대해 선형 결합($WX+b$)을 수행하는 것입니다.
- $$ \log\left(\frac{p}{1-p}\right) = WX + b $$
- 우리가 진짜 알고 싶은 것은 확률 $p$이므로, 식의 양변에 지수($e$)를 취해 정리해 봅니다.
$$ \frac{p}{1-p} = e^{WX + b} \quad \Rightarrow \quad p = \frac{e^{WX + b}}{1 + e^{WX + b}} $$
시그모이드(Sigmoid)의 탄생과 오차(Loss)
- 위 식 형태를 정리하면 우리가 잘 아는 시그모이드 함수가 탄생합니다.
- 로지스틱 손실 함수 (이진 크로스 엔트로피 / BCE): 모델 확률 예측에 대한 진짜 오차 공식입니다. (정답 $y$가 0일 때와 1일 때 작동식이 다름)
$$ p = \frac{1}{1 + e^{-(WX + b)}} $$
$$ Loss(BCE) = - \frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right] $$
6. 소프트맥스 (Softmax) 회귀
- 다중 분류(Multi-class) 모델의 최종 관문
- 각 클래스의 날것의 점수(Logits)들을 합산 비율에 맞춰 총합 1.0(100%)의 확률 분포로 정규화
- 목표: 정답 분포 [1, 0, 0, 0] 와 예측 분포 [0.5, 0.2, 0.2, 0.1] 사이의 오차 거리를 좁히는 것
7. 다중 크로스 엔트로피 공식 (CE)
- 이진 분류의 BCE 공식을 다중 클래스(수많은 선택지)로 모델을 확장시킨 완결판 공식입니다.
- 수많은 예측 확률값 중, 오직 정답 클래스($y_{i,c}=1$)에 대한 예측 확률값에만 $-\log$ 연산을 수행해 Loss 산출
- 결론: "정답인 항목의 확률을 얼마나 높게 예측했는가?" 만을 평가하는 효율적인 지표입니다.
$$ Loss(CE) = - \frac{1}{n} \sum_{i=1}^{n} \sum_{k=1}^{C} y_{i,c} \log(\hat{y}_{i,c}) $$
8. Next Week
- 챕터 진도 및 복습 (ch6, mml 1~3)
: 시험기간 전 주를 고려하여 수학 복습 중심으로 진행합니다. - 수학 보충 학습 자료
: 수학 참고 링크 (클릭) - L1, L2 Regularization (과제)
: 수식이 어떻게 모델의 과적합을 막아내는지 정리해보기